Beyond the click
Most experimentation stops at statistical significance. Declare a winner. Ship it and move on. But how do you know whether that "winner" built something lasting or just manufactured a short-term spike? This is how.
Start here
The framework
Conversion rate tells you someone completed an action. These three metrics tell you whether that action was the start of something worth having.
The total revenue a customer generates across their entire relationship with you.
Whether people come back, buy again, and recommend you to others over time.
How people feel about individual moments: a checkout, a support call, an onboarding flow.

Lifetime value
If you're spending more to acquire a customer than they'll ever generate, you need to know that. CLV is the metric that tells you.
Simplest model there is. What do they spend on average, how often, and for how long? Multiply those three together and you've got a number. Not a perfect number, but a starting point.
Revenue is not profit. A customer generating £1,000 at 25% margin is worth £250 in actual money you get to keep. The margin-adjusted version stops you lying to yourself about what a customer is really worth.
For subscription businesses, the formula is about how long someone sticks around before they leave. Average revenue per account of £100/month, 80% gross margin, 5% monthly churn? Your CLV is £1,600. That's your ceiling for what each customer relationship is worth.
The ratio that matters here is CLV to CAC (customer acquisition cost). You want roughly 3:1. Below 1:1 means you're paying more to get customers than they'll ever return. That's not growth. That's a bonfire.
Full CLV takes months or years to materialise. You can't wait that long for every experiment. Track these instead. They predict long-term value without making you wait for it.
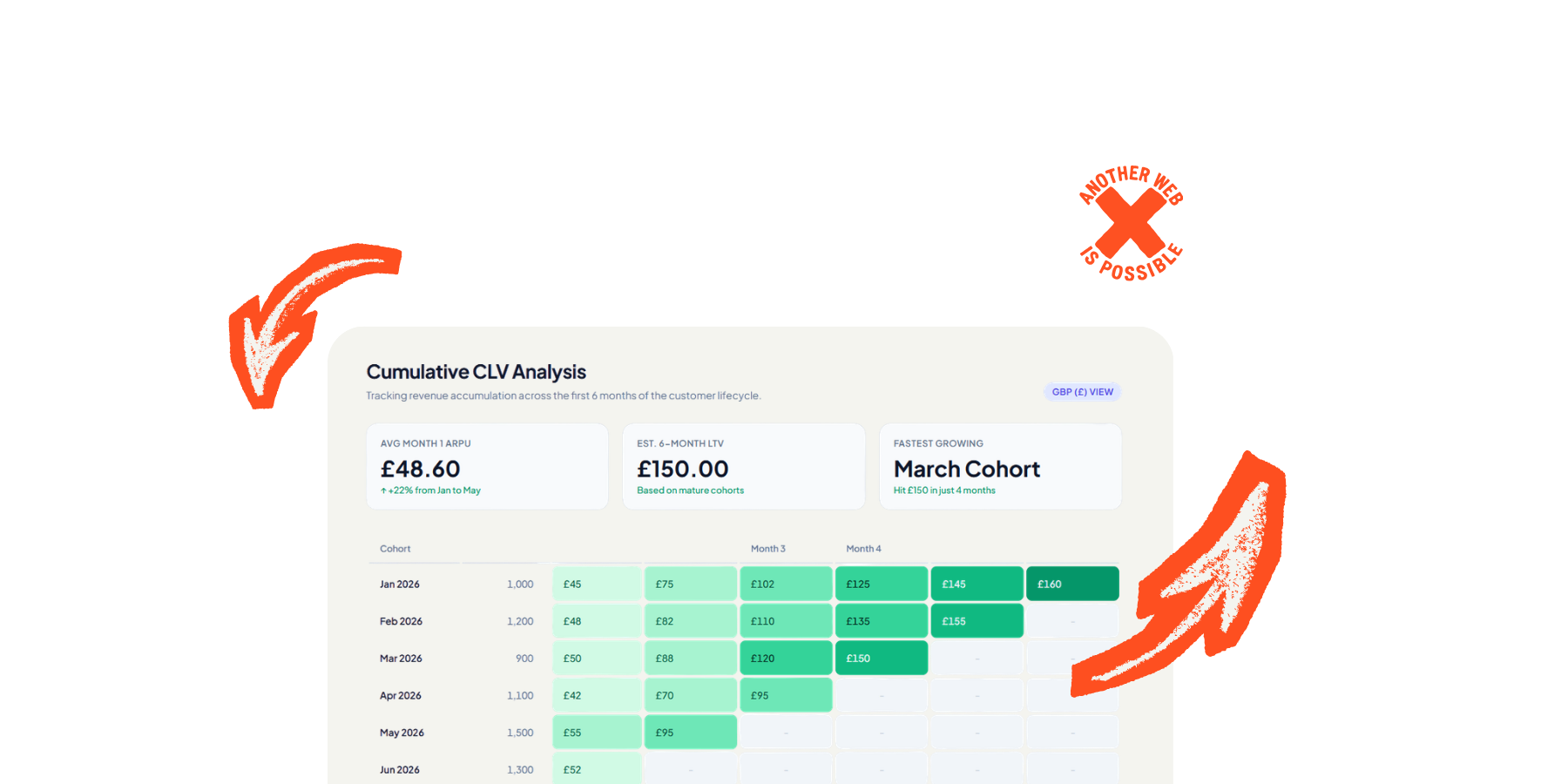
LTV7, LTV30, LTV90. Revenue generated within 7, 30, or 90 days of acquisition. LTV7 is a surprisingly strong predictor of full lifetime value. Move first-week revenue and you're almost certainly moving the long-term number too.
Percentage of customers who come back and buy again. The second purchase is always the hardest. If an experiment increases repeat buying, it's building genuine value. If it only moves first purchases, it might just be better at persuading people to try something they won't stick with.
How many features someone uses in their first week or month. Deeper adoption correlates strongly with retention and lifetime value, especially in SaaS. Shallow users churn. Embedded users stay.
Inverse indicator. More tickets usually predicts churn. If your experiment boosts conversion but also boosts support load, the short-term win is probably hiding a long-term problem.
Plug your numbers in. See what a customer is actually worth to you.
Loyalty
Conversion rate measures a single action. Loyalty measures whether the relationship behind that action is growing or shrinking.
One question: "How likely are you to recommend us to a friend or colleague?" Respondents land in three buckets. Promoters (9-10), Passives (7-8), and Detractors (0-6). Subtract detractors from promoters. That's your score. Range is -100 to +100.
More detractors than promoters. Something is fundamentally wrong and you should probably find out what before you run any more experiments.
Solid. Most people are satisfied. Room to improve but the foundations are there.
Strong to exceptional. Real loyalty, real advocacy. Whatever you're doing, keep doing it.
The follow-up matters more than the score. NPS on its own tells you nothing about why. Always pair it with an open-ended follow-up: "What's the main reason for your score?" The number opens the door. The follow-up is where the useful information actually lives. A score of 35 means nothing without context. A score of 35 with 200 written responses explaining what's wrong is a goldmine.
RFM (Recency, Frequency, Monetary) segments customers by what they actually do rather than what they say they'll do. No surveys. No response bias. Just behaviour.
How recently they bought something. More recent means more engaged. Score 1-5, with 5 being the most recent.
How often they buy. Higher frequency signals deeper loyalty and habit. A repeat customer is worth far more than someone who bought once and disappeared.
How much they spend. Combined with frequency, this tells you whether they're spending more or less over time. Trajectory matters more than the absolute number.
Combine the three scores for segments like Champions (5-5-5), At Risk, or Lost. Shopify, Klaviyo, and Optimove calculate this automatically. Or do it yourself in a spreadsheet. For digital products where spend isn't the main metric, swap Monetary for Engagement (RFE model) and track session depth, features used, or pages viewed instead.
Retention curves are the most honest picture of product health you can get. Group users into cohorts by when they signed up, then track what percentage are still active at Day 7, 30, 60, 90, 180, 365.
The shape tells you everything. A sharp initial drop followed by a plateau? Good. Users who survive the first week tend to stick. A curve that just keeps declining and never flattens? You haven't found a floor of genuinely engaged users yet. That's the problem to solve before you optimise anything else.

Bain & Company found that improving retention by just 5% can lift profit by 25-95%. Small retention gains compound massively. This is why long-term measurement matters more than whatever your last A/B test did to conversion rate this week.
Amplitude and Mixpanel handle advanced cohort retention analysis well. GA4 does the basics but falls over on multi-criteria cohorting. For full control, export to BigQuery and join product data with CRM and payment data in SQL.
Satisfaction
NPS gives you the big picture. These three metrics tell you what's happening in the moments that make or break the relationship.
| CSAT | CES | NPS | |
|---|---|---|---|
| Measures | Satisfaction with a specific interaction | How easy it was to do something | Overall loyalty and recommendation |
| Time horizon | Immediate, transactional | Immediate, operational | Long-term, relational |
| Best used | After purchases, support, updates | After checkout, onboarding, support | Quarterly, before/after big changes |
| Key insight | Which touchpoints are failing | Better loyalty predictor than CSAT | Brand health over time |
They work together. NPS tells you the relationship is suffering. CSAT tells you which touchpoint caused it. CES tells you whether the problem is the thing itself or how hard it is to use. Low NPS plus high effort score? The issue is friction, not product quality. Fix the journey before you fix the features.

How to actually do this
You can't measure lifetime value with a two-week test. Here's how to bridge the gap between how long experiments run and how long impact actually takes to show up.
Wiring it up
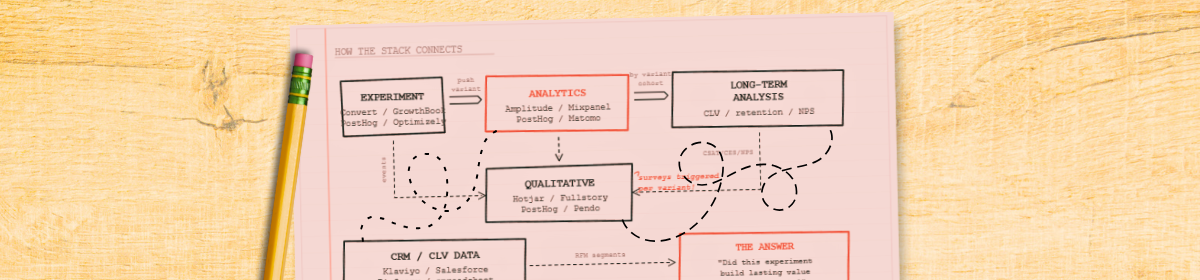
Individual tools do nothing useful in isolation. Here's how to connect them so experiment data flows into long-term measurement.
Fire NPS, CSAT, or CES surveys only at users in specific experiment variants. Compare satisfaction between control and treatment. Hotjar triggers surveys via custom events tied to variants. Qualaroo and Pendo can target by URL parameters or feature flag state. This is how you catch deceptive patterns before they ship.
Export experiment assignments and behavioural data to BigQuery, Snowflake, or Redshift. Run SQL joining experiment exposure to CLV, retention, and satisfaction over any time horizon you like. Eppo and GrowthBook are built for exactly this pattern. Maximum flexibility, maximum control.
If your experimentation programme only measures short-term conversion, you're implicitly saying you don't care whether changes help or harm users over time. That's a choice. Most companies don't realise they're making it.
Long-term measurement is a built-in check against manipulation. Track satisfaction alongside conversion and you'll see when a "winning" variant wins because it made things harder to refuse, not better to use. Track CLV alongside acquisition and you'll notice when aggressive tactics bring in people who'll be gone in a month. The tools aren't neutral. What you choose to measure shapes what you choose to build.
Need help? Let's talk